常用函数式接口
# 常用函数式接口
# 概述
只有一个抽象方法的接口我们称之为函数接口,不包含default默认的方法。
其中JDK自带的函数式接口还加上了@FunctionalInterface注解进行标识。
# 常见的函数式接口
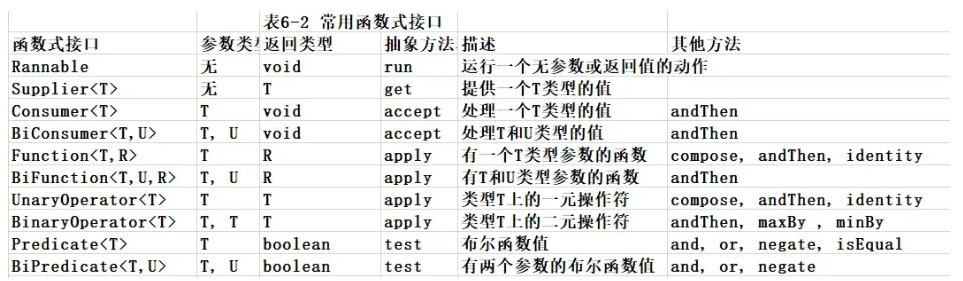
# Consumer 消费接口
根据抽象方法的参数列表和返回类型知道,我们可以在方法中对传入的参数进行消费(操作)
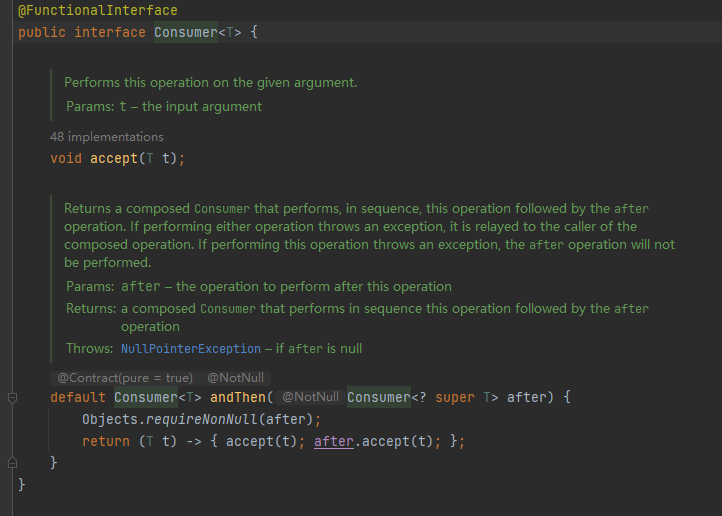
# Function 计算转换接口
我们可以在方法中对传入的参数计算或转化,把结果返回
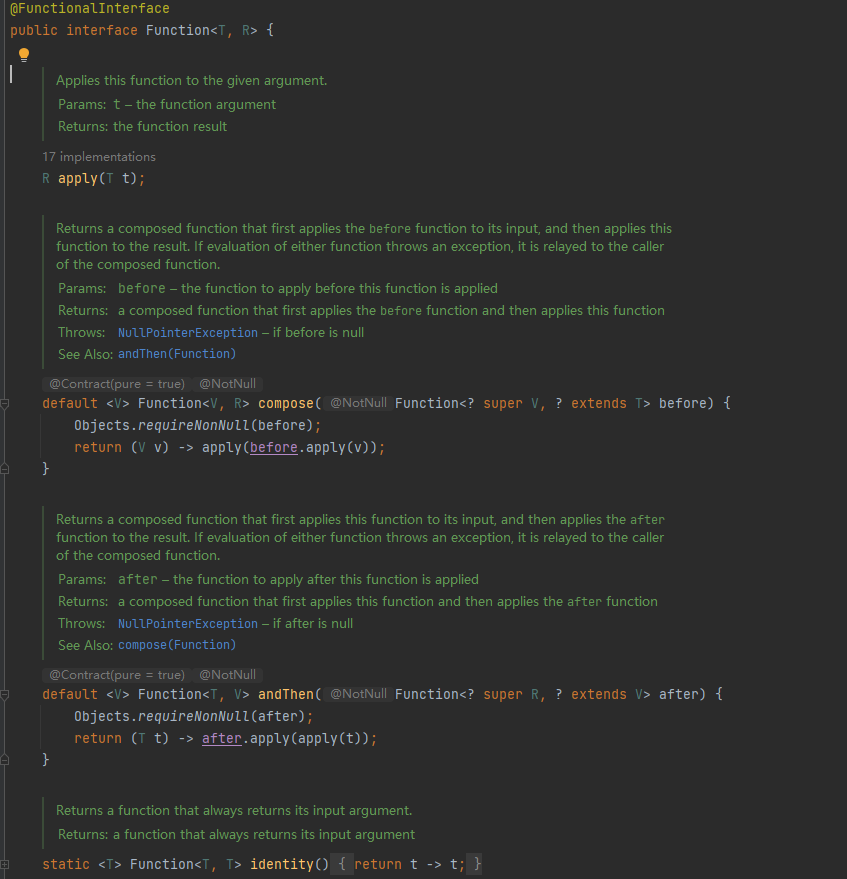
# Predicate 判断接口
我们可以在方法中对传入的参数条件判断,返回判断结果。
# supplier 生产型接口
我们可以在方法中创建对象,把创建好的对象返回。
# 常用的默认方法
# and
我们在使用Predicate接口时候可能需要进行判断条件的拼接。而and方法相当于是使用**&&**来拼接两个条件。
//打印输出所有成年且作品在一部以上的作家名字
authors.stream()
.filter(author -> author.getAge()>18)
.filter(author -> author.getBooks().size()>1)
.map(author -> author.getName())
.forEach(name-> System.out.println(name));
authors.stream()
.filter(author -> author.getAge()>18&&author.getBooks().size()>1)
.map(author -> author.getName())
.forEach(name-> System.out.println(name));
//使用接口
authors.stream()
.filter(new Predicate<Author>() {
@Override
public boolean test(Author author) {
return author.getAge()>18;
}
}.and(new Predicate<Author>() {
@Override
public boolean test(Author author) {
return author.getBooks().size()>1;
}
})
).map(author -> author.getName())
.forEach(name-> System.out.println(name));
//使用Lambda表达式
authors.stream()
.filter(((Predicate<Author>) author -> author.getAge() > 18).and(author -> author.getBooks().size()>1)
).map(author -> author.getName())
.forEach(name-> System.out.println(name));
# or
我们在使用Predicate接口时候可能需要进行判断条件的拼接。而and方法相当于是使用||来拼接两个判断条件。
//打印输出未成年或作品大于1的作家信息
authors.stream().filter(new Predicate<Author>() {
@Override
public boolean test(Author author) {
return author.getAge()<18;
}
}.or(new Predicate<Author>() {
@Override
public boolean test(Author author) {
return author.getBooks().size()>1;
}
})).forEach(author -> System.out.println(author));
authors.stream().filter(((Predicate<Author>) author -> author.getAge() < 18)
.or(author -> author.getBooks().size()>1))
.forEach(author -> System.out.println(author));
# negate
//打印出不小于18岁的作家姓名
authors.stream()
.filter(new Predicate<Author>() {
@Override
public boolean test(Author author) {
return author.getAge()<18;
}
}.negate()).map(author -> author.getName())
.forEach(name-> System.out.println(name));
authors.stream()
.filter(((Predicate<Author>) author -> author.getAge() > 18).negate()
).map(author -> author.getName())
.forEach(name-> System.out.println(name));
# 方法引用
我们使用Lambda表达式时,如果方法体中只有一个方法调用的话,我们可以进一步简化代码。
# 基本格式
类名或者对象名::方法名
authors.stream()
.filter(new Predicate<Author>() {
@Override
public boolean test(Author author) {
return author.getAge()<18;
}
}.negate()).map(Author::getName)
.forEach(name-> System.out.println(name));
# 基本类型优化
使用Stream的方法由于都是用到泛型,所以涉及到的参数和返回值都是引用类型。
我们操作整数小数,实际上使用的是他们的包装类。当数据很多的时候自动拆装箱非常浪费资源。
所以为了避免这些造成的时间消耗,Stream提供了很多专门针对于基本数据类型的方法。
例如:mapToInt,mapToLong,mapToDouble,flapMapToInt,flapMapToDouble等
authors.stream()
.map(author -> author.getAge())
.map(age -> age+10)
.forEach(System.out::println);
//避免后续操作的拆装箱
authors.stream()
.mapToInt(author -> author.getAge())
.map(age -> age+10)
.forEach(System.out::println);
# 并行流
当流中有大量元素时,我们可以使用并行流去提高操作效率。并行流分配给多个线程,而且不用考虑线程安全问题,很方便。
//计算总年龄
int asInt = authors.stream()
.flatMap(author -> author.getBooks().stream())
.peek(book -> System.out.println(book.getId()+ Thread.currentThread().getName()))
.mapToInt(book -> book.getScore())
.reduce((result, ele) -> result + ele)
.getAsInt();
System.out.println(asInt);
1main
2main
3main
4main
5main
471
//计算总年龄
int asInt1 = authors.parallelStream()
.flatMap(author -> author.getBooks().stream())
.peek(book -> System.out.println(book.getId()+ Thread.currentThread().getName()))
.mapToInt(book -> book.getScore())
.reduce((result, ele) -> result + ele)
.getAsInt();
System.out.println(asInt1);
4main
5main
1ForkJoinPool.commonPool-worker-25
2ForkJoinPool.commonPool-worker-25
3ForkJoinPool.commonPool-worker-25
471
# Lambda表达式懒加载
lambda 表达式的重点是延迟执行 (deferred execution)
好处:
在一个单独的线程中运行代码;
多次运行代码;
在算法的适当位置运行代码(例如,排序中的比较操作);
发生某种情况时运行代码(如,点击了一个按钮,数据已经到达,等等);
只在必要时才运行代码。
package com.yuwei.reflect;
import java.time.LocalDateTime;
import java.util.function.Supplier;
public class AATest {
public static void main(String[] args) {
System.out.println(LocalDateTime.now());
lambda1(true,testString());
System.out.println(LocalDateTime.now());
lambda1(false,testString());
System.out.println(LocalDateTime.now());
lambda2(true,()->testString());
System.out.println(LocalDateTime.now());
lambda2(false,()->testString());
System.out.println(LocalDateTime.now());
}
public static String testString(){
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("调用testString");
return "testString";
}
public static void lambda1(boolean flag,String msg){
if(flag){
System.out.println(msg);
}
}
public static void lambda2(boolean flag, Supplier<String> supplier){
if(flag){
supplier.get();
}
}
}
如上面代码所示,
调用lambda1(false,testString());不管第一个参数是不是true,都会调用testString()。当testString()用的时间过长的话,非常影响性能。用lambda表达式即可解决该问题。
2023-12-18T13:42:55.350
调用testString
testString
2023-12-18T13:42:57.353
调用testString
2023-12-18T13:42:59.362
调用testString
2023-12-18T13:43:01.370
2023-12-18T13:43:01.370
