SQL优化基础知识
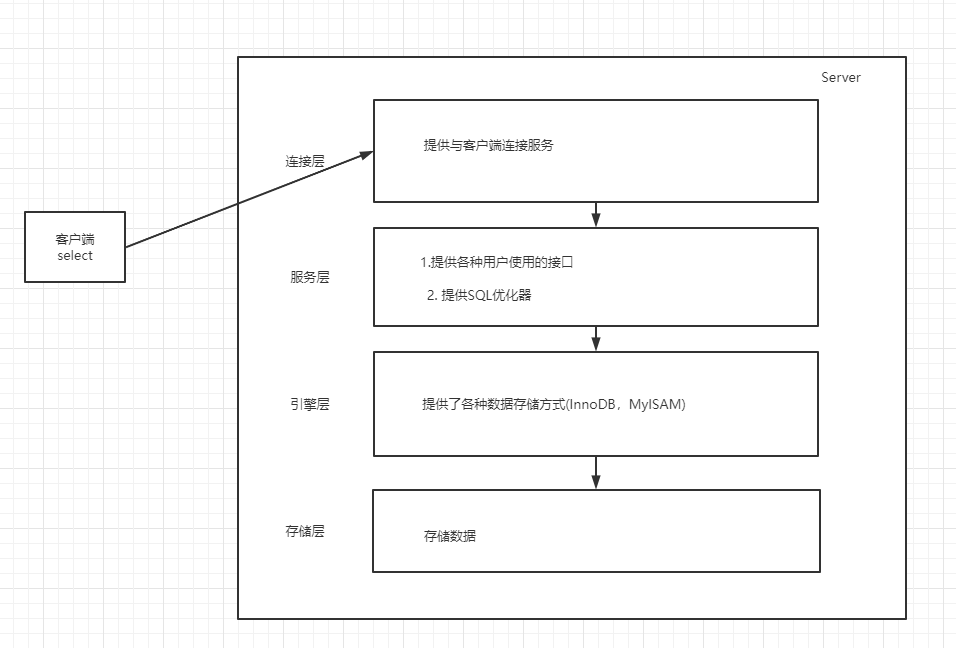
# MySQL分层
InnoDB与MyISAM引擎的区别
InnoDB : 事物优先,适用于高并发操作,行锁
MyISAM:性能优先;表锁
# SQL优化方向
性能低、执行时间长、等待时间长、SQL语句欠佳、索引失效、服务器参数设置不合理(缓冲、线程);
# SQL执行过程
编写过程 :
select distinct .. from .. join .. on .. where .. group by .. having .. order by .. limit ..
解析过程:
from .. on .. join .. where .. group by .. having .. select distinct .. order by .. limit ..
具体可以详见:
MySQL查询执行流程-SQL解析顺序 - Saltery - 博客园 (cnblogs.com) (opens new window)
# 索引
# 优化索引
索引:相当于书的目录,index是帮助MySQL高校获取数据的数据结构。(默认B树)
使用索引的弊端:
- 索引本身很大,可以存放在内存/硬盘
- 索引不适用于:少量数据、频繁更新的字段(会影响树的结构)、很少使用的字段
- 索引会降低增删改的效率
使用索引的优势:
- 提高查询效率(降低IO使用率)
- 降低CPU使用率
# 索引分类
单值索引:单列;一个表中可以有多个单值索引 (name)
唯一索引:不能重复,(id) 可以是NULL
主键索引:不能重复,比如主键 (id) 不能是NULL
复合索引:多个列构成的索引(相当于二级目录)(name,age) 如果第一个全部命中,例如找张三,整个库里只有一个张三,那么查找到此为止,不会在去查找age了。
# 创建索引
- 方式一:
create 索引类型 索引名 on 表(字段)
单值索引:给STUDENT表的NAME建一个名为name_index的索引
create index name_index on STUDENT(NAME);
唯一索引:给STUDENT表的id建一个名为id_index的唯一索引
create unique index id_index on STUDENT(ID);
复合索引:给STUDENT表的DEP、NAME建一个名为dep_name_index的复合索引
create index dep_name_index on STUDENT(DEP,NAME);
- 方式二:
alter table 表名 add 索引类型 索引名(字段)
注意:如果一个字段是主键、那么他默认就是主键索引
# 删除索引
drop index 索引名 on 表名;
删除STUDENT表的id_index索引
DROP index id_index on STUDENT;
# 查询索引
show index from 表名;
查询STUDENT表有哪些索引
show index from STUDENT ;
# SQL性能问题
分析SQL执行计划
explain SQL语句
例如:
explain SELECT * from STUDENT where Id = '1' ;
| id(编号) | select_type(查询类型) | table(表) | type(类型) | possible_keys(预测用到的索引) | key(实际使用的索引) | key_len(实际使用的长度) | ref(表之间的引用) | rows(通过索引筛选的数据) | filtered |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | STUDENT | ref | id_index | id_index | 5 | const | 1 | 100.0 |
数据准备:
create table course(
cid int(3),
cname varchar(20),
tid int(3)
);
create table teacher(
tid int(3),
tname varchar(20),
tcid int(3)
);
create table teacherCard(
tcid int(3),
tcdesc varchar(200)
);
INSERT into course values(1,'java',1);
INSERT into course values(2,'html',1);
INSERT into course values(3,'sql',2);
INSERT into course values(4,'web',3);
INSERT into teacher values(1,'tz',1);
INSERT into teacher values(2,'tw',2);
INSERT into teacher values(3,'tl',3);
INSERT into teacherCard values(1,'tzdesc');
INSERT into teacherCard values(2,'twdesc');
INSERT into teacherCard values(3,'tldesc');
# explain的用法
# 数据准备
create table course(
cid int(3),
cname varchar(20),
tid int(3)
);
create table teacher(
tid int(3),
tname varchar(20),
tcid int(3)
);
create table teacherCard(
tcid int(3),
tcdesc varchar(200)
);
INSERT into course values(1,'java',1);
INSERT into course values(2,'html',1);
INSERT into course values(3,'sql',2);
INSERT into course values(4,'web',3);
INSERT into teacher values(1,'tz',1);
INSERT into teacher values(2,'tw',2);
INSERT into teacher values(3,'tl',3);
INSERT into teacherCard values(1,'tzdesc');
INSERT into teacherCard values(2,'twdesc');
INSERT into teacherCard values(3,'tldesc');
# 联表查询
查询cid为2,或者tcid为3的教师证信息。
SELECT tc1.* from course cs,teacher tc,teacherCard tc1 where cs.tid = tc.tid and tc1.tcid = tc.tcid and (cs.cid = '2' or tc.tcid = '3');

id值相同,从上到下,顺序执行
# 子查询
id值不同,由大到小,顺序执行 cs->teacher->tc1 ,从最内层顺序查询
SELECT * from teacherCard tc1 where tc1.tcid = (SELECT tcid from teacher where tid = (SELECT tid from course cs where cs.cid = '2'));

# 子查询加联表
id值越大越执行,然后在按照从上往下执行
SELECT * from teacherCard tc1 where tc1.tcid = (SELECT t.tcid from teacher t ,course c where t.tid = c.tid AND c.cid = '2');

# SelectType查询类型
Primary:包含子查询SQL的主查询(最外层)
SubQuery:包含子查询SQL中的子查询(非最外层)
Simple:简单查询 (不包含子查询和union查询)
derived:衍生查询 (union查询)

# Type索引类型
type优化前提是有索引
效率从高到低 system>const>eq_ref>>ref>range>index>all
其中:system,const只是理想状态 实际上ref>range>
# 了解
system:
- 只有一条数据的表
- 衍生表只有一条数据
const:
- 仅仅能查到一条数据的sql
- 必须使用主键索引或唯一索引
eq_ref:
- 索引所在列每一条数据都是唯一的数据,不可重复。比如name,只有一个人叫张三。
- 常见于唯一索引与主键索引
# 掌握
ref:
- 非唯一性索引
- 返回0或多条数据
INSERT into teacher values(4,'tz',4);
create index tname_index on teacher(tname);
SELECT * from teacher where tname = 'tz';
explain SELECT * from teacher where tname = 'tz';

range:
检索索引范围的行 > , < ,>=,<=,between,in(有时会失效,转为无索引all)
create index tid_index on teacher(tid);
explain SELECT * from teacher t where tid > 1;
explain select * from teacher t where tid BETWEEN 1 and 4;
explain SELECT * from teacher t where tid >= 2;
explain SELECT * from teacher t where tid < 2;
explain SELECT * from teacher t where tid <= 2;
explain select * from teacher t where tid in (1,3);

index:
检索所有索引的数据,只需查询索引表数据
explain SELECT tid from teacher;

all:
检索数据表所有的数据,会查询数据表所有数据
比如,我们teacher表中的tcid未加索引,实际上查询tcid时会全表数据扫描,tid和tname也会被扫描
explain SELECT tcid from teacher t ;

# possible_keys 和 key
可能执行的索引与实际执行的索引
# Key_len
索引的长度
作用:用于判断复合索引是否被完全使用
utf-8 一个字符三个字节
gbk 一个字符两个字节
latin 一个字符一个字节
# ref
与type的ref 不是一个概念
作用:知名当前表所参照的字段
# rows
实际通过索引查到的数据个数
# Extra
# using filesort
代表性能消耗大 需要额外的一次排序,一般出现在order by
排序: 需要先进行查询,在进行排序
- 单索引
例如: select * from User where userid = 'lucy' order by name
假设userid是单索引,这个extra就是fileSort ,因为按照name进行排序,又要先进行一次查询再排序。
注:如果排序和查询的是同一个字段就不会出现该种情况。
- 复合索引
例如:select * from User where userid = 'lucy' order by name;
假设复合索引 ina_index(userid,name,age)
如果是这样就不会出现using filesort,但如果 order by age就会。
注:不能跨列,且必须从最左边的索引开始
# using tempory
代表性能消耗大 需要额外的创建一次临时表,一般出现在group by
例如: explain SELECT tid from teacher where tid in('2') group by tcid ;
where查询了tid列,但是根据tcid排序,又会多一次查询操作
# using index
性能提升;索引覆盖。
- 单索引
假设age是索引列
select age from teacher where age = '';
- 复合索引
假设age、name是复合索引
select age,name from teacher where age = ' ' or name = '';
不读原文件,只从索引文件进行检索,不需要回表查询,所用的列也全部在索引中。
# using where
- 单索引
假设age 是索引列,要查询Name必须回原表查Name
select age,name from teacher where age = ''
- 复合索引
# Extra其他举例
create table test03
(
a1 int(4) not null,
a2 int(4) not null,
a3 int(4) not null,
a4 int(4) not null
)
alter table test03 add index idx_a1_a2_a3_a4(a1,a2,a3,a4);
1、 最佳SQL:查询where条件按照索引顺序来
select a1,a2,a3,a4 from test03 where a1=1 and a2=2 and a3=3 and a4=4;

2、
select a1,a2,a3,a4 from test03 where a1=1 and a2=2 and a4=3 order by a3;

该SQL Extra字段包含Using where; Using index
说明该SQL部分回表
分析:a1,a2两个总段不需要回表查询,而a4跨列需要回表查询
3、
select a1,a2,a3,a4 from test03 where a1=1 and a4=2 order by a3;

多了using fileSort说明多排序了一次
where 和 order by 拼起来不要跨列
# 为什么会出现有的失效
2号SQLwhere条件 a1,a2 a4索引失效,因此order by a3刚好赶上a1,a2,a3的索引,因此不会失效
3号1,3跨列
# 总结
- 如果(a,b,c,d)复合索引 和使用的顺序全部一致,则复合索引全部使用。如果部分一致,则使用部分索引
- where和order by 拼起来需要保持顺序
最左原则,不跨列使用
